The EVENTA 2025 Grand Challenge focuses on image-caption retrieval and generation. We aim to integrate contextual details and event-related information to create comprehensive, narrative-driven captions that go beyond simple visual analysis. Therefore, the captions provide richer, more comprehensive information about an image. These captions go beyond simple visual descriptions by offering deeper insights, including the names and attributes of objects, the timing, context, outcomes of events, and other crucial details - information that cannot be gleaned from merely observing the image.
🚀 Top-ranked teams will be invited to submit a paper to ACM Multimedia and present at the conference, subject to peer review.
To participate in the EVENTA 2025 Grand Challenge, please first register by submitting the form.
This track aims to generate captions that provide richer, more comprehensive information about an image. These captions go beyond simple visual descriptions by offering deeper insights, including the names and attributes of objects, the timing, context, outcomes of events, and other crucial details—information that cannot be gleaned from merely observing the image. Given an image, participants are required to search relevant articles in a provided external database and extract necessary information to enrich the image caption. This retrieval augmentation generation track facilitates the creation of more coherent and detailed narratives, capturing not only the visible elements but also the underlying context and significance of the scene, ultimately offering a more complete understanding of what the image represents. More details here.
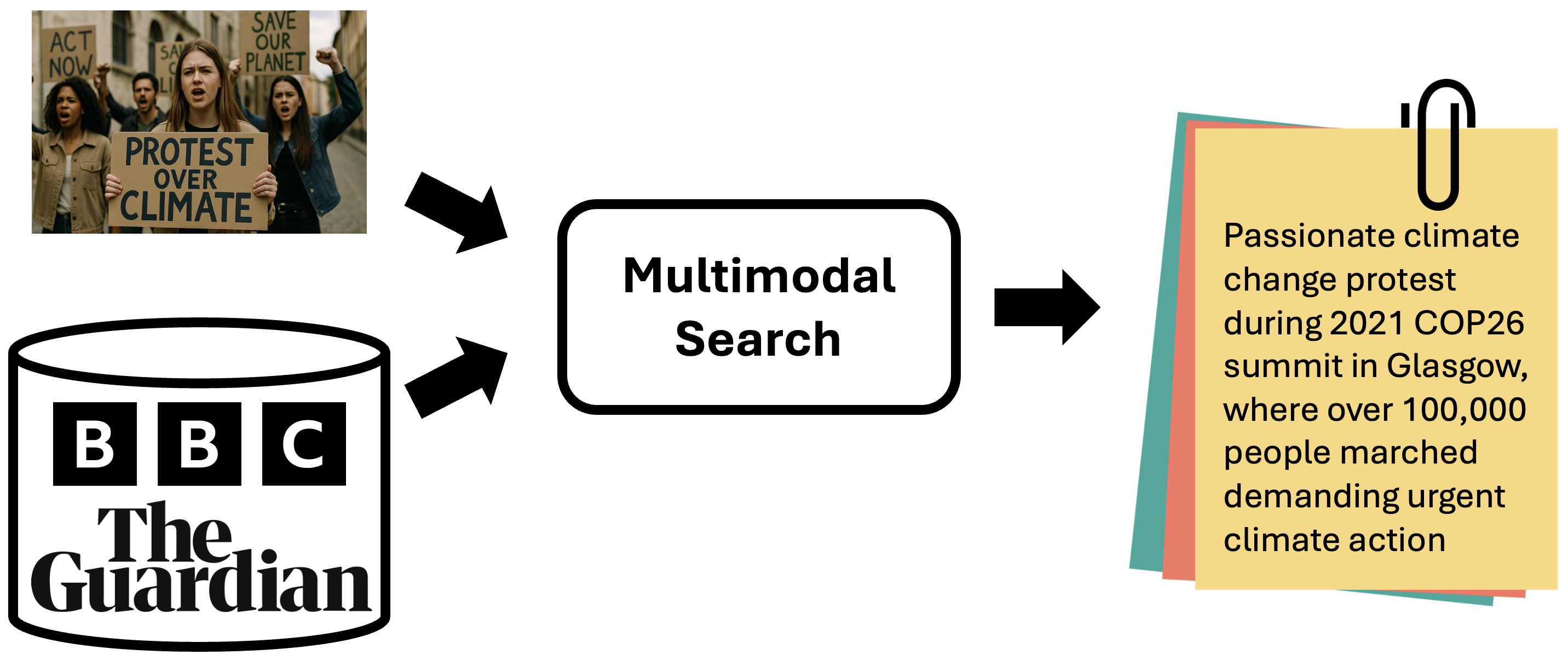
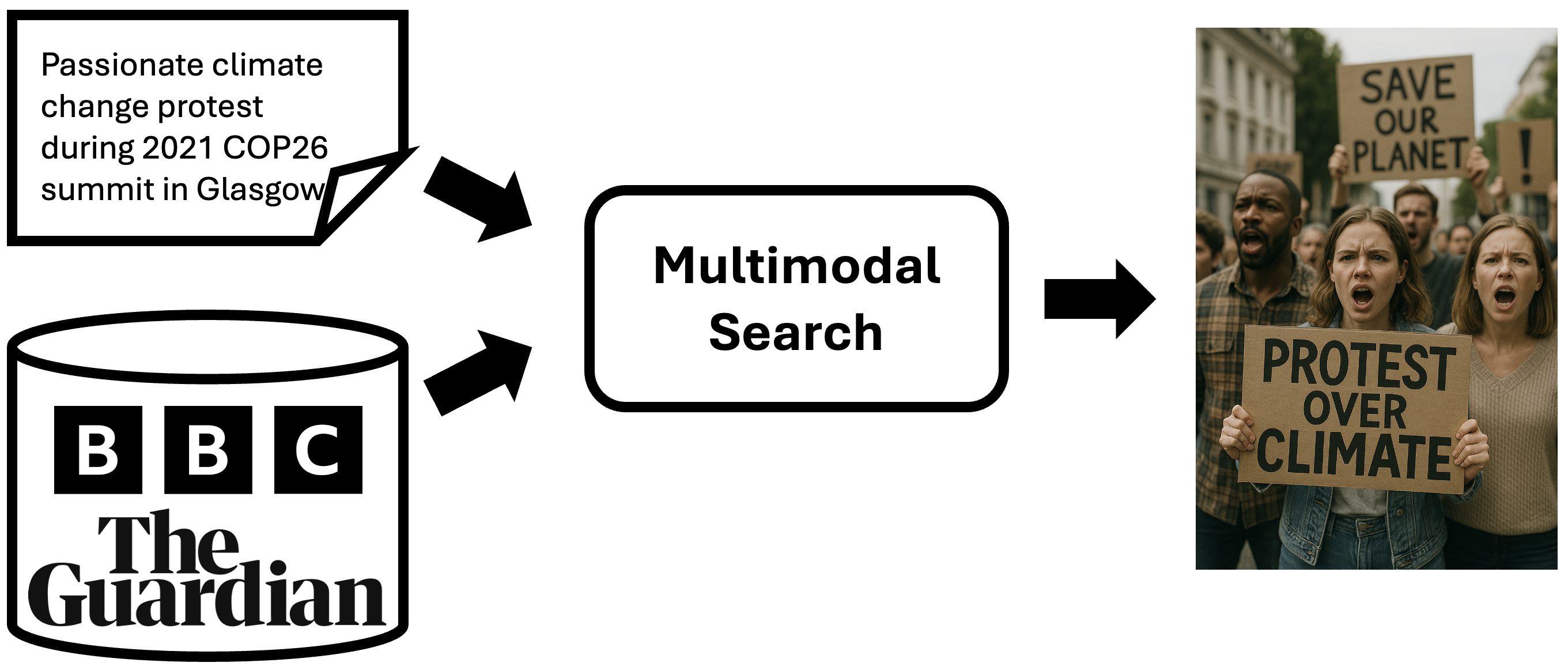
Given a realistic caption, participants are required to retrieve corresponding images from a provided database. This retrieval task is a fundamental task in computer vision and natural language processing that requires learning a joint representation space where visual and textual modalities can be meaningfully compared. Image retrieval with textual queries is widely used in search engines, medical imaging, e-commerce, and digital asset management. However, challenges remain, such as handling abstract or ambiguous queries, improving retrieval efficiency for large-scale datasets, and ensuring robustness to linguistic variations and biases in training data. This image retrieval track aims to tackle issues of realistic information from events in real life. More details here.
- Participants are not allowed to annotate the test sets.
- External datasets are permitted. However, participants may only use publicly accessible datasets and pre-trained models. The use of private datasets or pre-trained models is strictly prohibited.
- Open sources are allowed. However, commercial tools, libraries, APIs, etc. are strictly prohibited.
- Final scores are calculated based on performance on the Private Test set.
- Participants must make their source code publicly available on GitHub to ensure reproducibility.
- Participants must submit a detailed paper through the official challenge platform before the deadline to validate their solutions.
- Late submissions will not be accepted.
- Only registered teams that submit papers are eligible to win, but all participants’ scores will be recognized.
EVENTA 2025 Grand Challenge uses OpenEvents V1 dataset.
We accept papers of up to 6 pages of content in the ACM MM format, plus up to 2 additional pages for references only. Paper submissions must conform with the “double-blind” review policy. Submission policies adhere to the ACM MM 2025 submission policies.
We recommend participants to cite the Challenge Overview paper written by the organizers. This paper contains all the necessary information on the challenge definition and the dataset. Therefore, participants do not need to repeat to describe the challenge or the dataset in details. Instead, participants can exclusively present the motivation for their approach, explaining their method, showing and analyzing their results, and giving an outlook on future work, etc.
Submit your paper here.
- Challenge opened: Apr. 01, 2025
- Team registration opened: Apr. 01, 2025
- Training set released: Apr. 18, 2025
- Public-test set released: May. 05, 2025
- Team registration deadline: Jun. 09, 2025
- Private-test set released:
Jun. 10, 2025 - Challenge closed:
Jun. 24, 2025 - Paper submission deadline: Jul. 01, 2025
- Acceptance notification: Jul. 24, 2025
- Camera-ready deadline: Aug. 26, 2025
- Challenge date: Otc. 31, 2025
- Cerebro Team, "ENRIC: EveNt-AwaRe Captioning with Image Retrieval via UnCertainty-Guided Re-ranking and Semantic Ensemble Reasoning". [PDF]
- SodaBread Team, "ReCap: Event-Aware Image Captioning with Article Retrieval and Semantic Gaussian Normalization". [PDF]
- NoResources Team, "EVENT-Retriever: Event-Aware Multimodal Image Retrieval for Realistic Captions". [PDF]
- Re:zero Slavery Team, "Beyond Vision: Contextually Enriched Image Captioning with Multi-Modal Retrieval". [PDF]
- ITxTK9 Team, "ZSE-Cap: A Zero-Shot Ensemble for Image Retrieval and Prompt-Guided Captioning". [PDF]
- HCMUS-NoName Team, "Hierarchical Multi-Modal Retrieval for Knowledge-Grounded News Image Captioning". [PDF]
- 23Trinitrotoluen Team, "A Hybrid Dense-Sparse Multi-Stage Re-ranking Framework for Event-Based Image Retrieval". [PDF]
- LastSong Team, "Hierarchical Article-to-Image: Leveraging Multi-Granularity Text Representations for Article Ranking and Text-Visual Similarity for Image Retrieval". [PDF]
- Sharingan Retrievers Team, "Leveraging Lightweight Entity Extraction for Scalable Event-Based Image Retrieval". [PDF]
- ZJH-FDU Team, "A Pretrained Model-Based Pipeline for Event-Driven News-to-Image Retrieval". [PDF]
Date: October 31st, 2025 (Friday), 9:00 AM – 10:30 AM (GMT+1)
Venue: Distillers, Hyatt at the Royal Dublin Convention Centre, Dublin, Ireland
Online: Zoom link
- 09:00 – 09:10 - Prof. Minh-Triet Tran: Opening Remarks
- 09:10 – 09:25 - Thien-Phuc Tran, et al. (online): Event-Enriched Image Analysis Grand Challenge at ACM Multimedia 2025
- 09:25 – 09:40 - Nam-Quan Nguyen, et al. (Cerebro Team - onsite): ENRIC: EveNt-AwaRe Captioning with Image Retrieval via UnCertainty-Guided Re-ranking and Semantic Ensemble Reasoning
- 09:40 – 09:55 - Thinh-Phuc Nguyen, et al. (SodaBread Team - online): ReCap: Event-Aware Image Captioning with Article Retrieval and Semantic Gaussian Normalization
- 09:55 – 09:10 - Dinh-Khoi Vo, et al. (NoResources Team - online): EVENT-Retriever: Event-Aware Multimodal Image Retrieval for Realistic Captions
- 09:10 – 10:25 - Minh-Loi Nguyen, et al. (HCMUS-NoName Team - online): Hierarchical Multi-Modal Retrieval for Knowledge-Grounded News Image Captioning
- 10:25 - Prof. Minh-Triet Tran: Closing Remarks
Thien-Phuc Tran, Minh-Quang Nguyen, Minh-Triet Tran, Tam V. Nguyen, Trong-Le Do, Duy-Nam Ly, Viet-Tham Huynh, Khanh-Duy Le, Mai-Khiem Tran, Trung-Nghia Le, "Event-Enriched Image Analysis Grand Challenge at ACM Multimedia 2025", ACM International Conference on Multimedia, 2025. [arXiv]





Contact: ltnghia@fit.hcmus.edu.vn




